Mining Social Media for Disaster Response
 © Sajid Sarker, 2022.
© Sajid Sarker, 2022.
Motivation
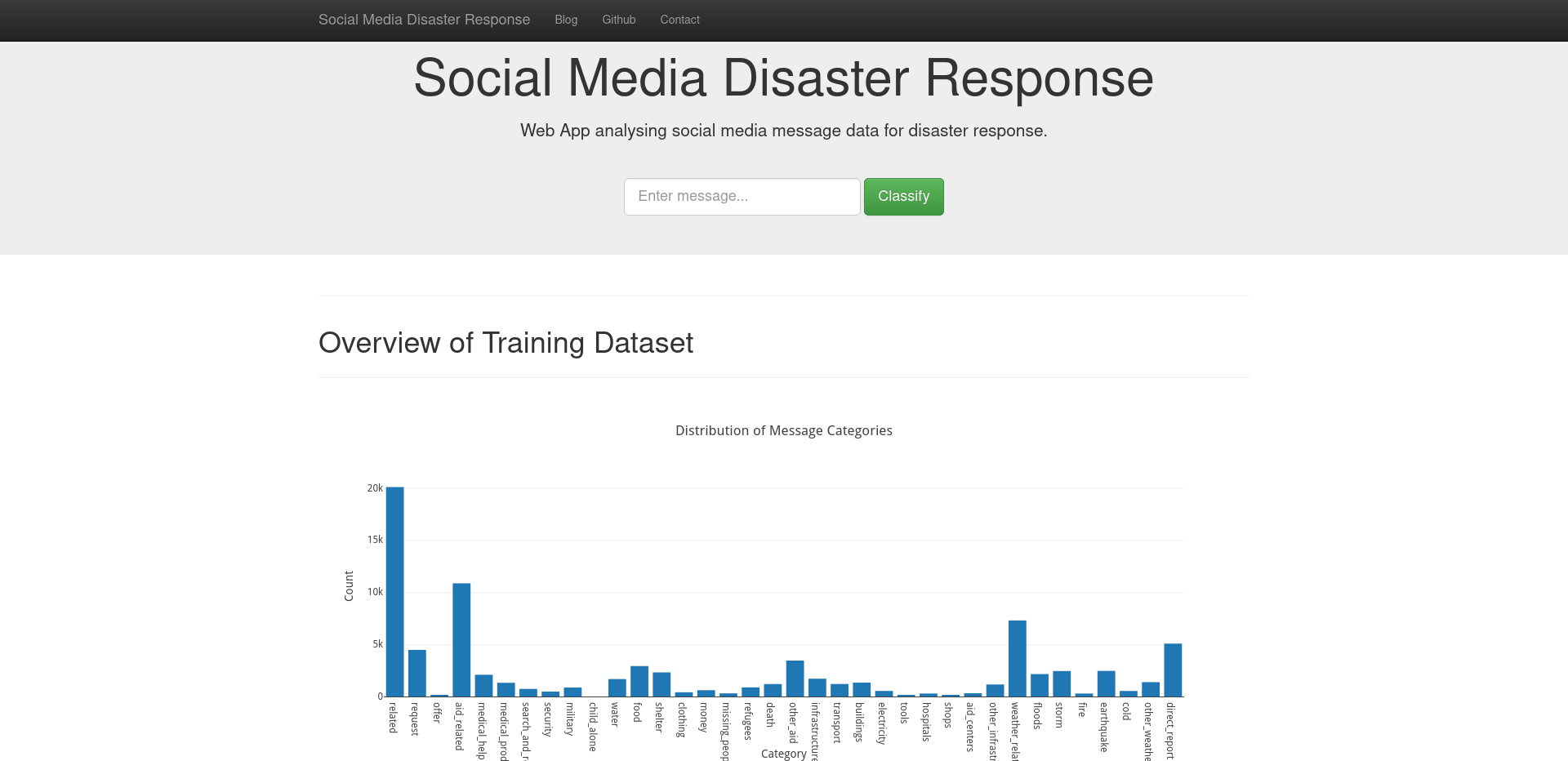
The motivation for this particular project is to construct a web-based application and API that is able to classify social media messages into critical disaster response-related categories. There are 36 predefined natural disasters and disaster response-related categories under which social media messages may be filed including earthquakes, floods, shelter, food, medical aid, search & rescue et cetera.
By classifying these messages, we can determine critical information on specific locations, users, and aid resources required for disaster relief efforts and forward the contents of these identified messages to the appropriate disaster relief agencies or governmental authorities for disaster response.
The utilisation of machine learning and natural language processing ensures faster alert and detection of social media content for disasters and identifying where, for whom, and what sort of relief response will be essential and effective in those circumstances.
The web-based application and API uses an ETL pipeline that processes social media disaster related messages from Figure Eight and subsequently uses the cleaned dataset in a NLP pipeline for a multi-class classification model.
Pipeline
Extract, Transform, Load (ETL):
The ETL pipeline that was developed to process our data was responsible for cleaning message and category datasets stored in a .CSV format and then converting it to a SQL database table.
Categories in the category dataset were essentially broken down into categorical binary dummy variables across multiple new columns and observational data was indexed by their respective unique message IDs in the message dataset. The two DataFrames were then merged together and converted into a SQL database table.
Natural Language Processing (NLP):
The NLP pipeline that was used to process message data took information from the SQL database table created by the ETL pipeline, and ran each message through various text processing steps.
These included:
- Text normalisation
- URL removal
- Punctuation removal
- Tokenisation
- Stopword removal
- Lemmatisation
Cleaned tokens were then vectorised by count and subsequently transformed to obtain TF-IDF.
Finally, the last stage of the pipeline was to conduct a Grid Search with Cross Validation on an Ada Boost classifier algorithm for Supervised Ensemble learning.
Open Source
[1] Github Repository: Disaster Response Pipeline Project